Pilot Testing Surveys: What to Test (and What Testing Won't Fix) (2026)
Pilot testing methods: cognitive interviews (comprehension), expert review (methodology), soft launches (field conditions). What each reveals.

Pilot testing is one of the most recommended and least understood practices in survey research. Everyone agrees you should do it. Few agree on what "it" actually means.
The result: teams run pilots that catch superficial issues while missing fundamental problems, then launch with false confidence because "we tested it."
This guide explains what different pilot testing methods actually reveal, what they miss, and how to avoid the trap of testing for the wrong things.
What Pilot Testing Actually Catches
Pilot testing primarily reveals usability and interpretation issues:
- Confusing question wording
- Ambiguous answer options
- Technical bugs and display problems
- Branching logic that doesn't work as intended
- Questions that take too long to answer
- Instructions that respondents skip or misunderstand
Willis (2005) documented that cognitive interviewing techniques reliably identify these surface-level problems. That's valuable. Confusing surveys produce bad data.
But here's what pilot testing doesn't catch:
What Pilot Testing Won't Fix
Construct validity problems
If your questions don't measure what you think they measure, no amount of testing will reveal that. A question about "satisfaction" might be perfectly clear to respondents while still failing to capture what actually drives their behavior.
Sampling frame issues
Pilot testing doesn't tell you if you're surveying the right people. Testing your employee survey with 10 employees doesn't reveal whether your sampling approach will miss entire departments.
Social desirability bias
Respondents in pilot tests are often aware they're being observed. This makes them more likely to give socially desirable answers, not less. The biases that affect real respondents may be amplified or hidden in pilot conditions.
Analysis problems
A survey can be perfectly clear and still produce data that's impossible to analyze meaningfully. Pilot testing doesn't reveal that your response scale will cluster everyone at the top or that your open-ended question will generate unusable text.
We've watched teams run a perfect pilot with 50 enthusiastic colleagues, then launch to real users who interpreted the same questions completely differently.
Three Types of Pilot Testing
1. Cognitive Interviews
What it is: One-on-one sessions where a facilitator watches respondents complete the survey while thinking aloud.
Sample size: 5-15 participants typically sufficient. Nielsen (2000) demonstrated that 5 users find approximately 85% of usability issues. For surveys, Presser et al. (2004) found that 10-15 cognitive interviews catch most interpretation problems.
What it reveals:
- How respondents interpret question wording
- Where they hesitate or express confusion
- What mental processes they use to formulate answers
- Which instructions they skip or misread
What it misses:
- Problems that only emerge at scale
- Technical issues across different devices
- How actual response distributions will look
- Whether your sample is representative
Best for: New question development, complex or sensitive topics, academic research requiring methodological rigor.
Protocol example:
- Ask respondent to complete survey while verbalizing thoughts
- Probe after each question: "How did you decide on that answer?"
- Note hesitations, confusion, reinterpretations
- After completion: "Were any questions unclear or hard to answer?"
2. Soft Launch
What it is: Releasing the survey to a small portion of your actual sample (typically 5-10%) and analyzing initial responses before full deployment.
Sample size: 50-100 responses, or 5-10% of target sample.
What it reveals:
- Completion rates and drop-off points
- Response time per question
- Technical issues across devices and browsers
- Actual response distributions
- Branching logic errors that only appear with real data
What it misses:
- Why people abandon (you only see that they did)
- Interpretation issues (you see answers, not thought processes)
- Problems specific to demographic subgroups not represented in soft launch
Best for: Large-scale surveys, technically complex surveys, surveys with extensive branching.
What to check:
- Overall completion rate (expect 10-20% lower than your target population baseline)
- Median completion time (is it reasonable?)
- Drop-off by question (sudden spikes indicate problem questions)
- Impossible answer patterns (people shouldn't rate the same thing both "excellent" and "poor")
- Device/browser distribution (matches your expected audience?)
3. Expert Review
What it is: Having survey methodology experts or subject matter experts review your instrument before any respondent testing.
Sample size: 3-5 experts.
What it reveals:
- Methodological best practice violations
- Leading or loaded questions
- Missing response options
- Logical inconsistencies
- Domain-specific errors (if using subject matter experts)
What it misses:
- How actual respondents (non-experts) interpret questions
- Usability issues that only appear in context
- Problems experts are blind to because of their expertise
Best for: Initial review before cognitive testing, resource-constrained projects, surveys on technical topics.
Comparison: What Each Method Finds
| Issue Type | Cognitive Interview | Soft Launch | Expert Review |
|---|---|---|---|
| Confusing wording | Excellent | Indirect | Good |
| Technical bugs | Limited | Excellent | No |
| Logic errors | Some | Excellent | Good |
| Completion time | Biased high | Accurate | No |
| Drop-off patterns | No | Excellent | No |
| Response distributions | No | Yes | No |
| Methodological errors | Some | No | Excellent |
| Interpretation issues | Excellent | No | Limited |
The Right Sequence
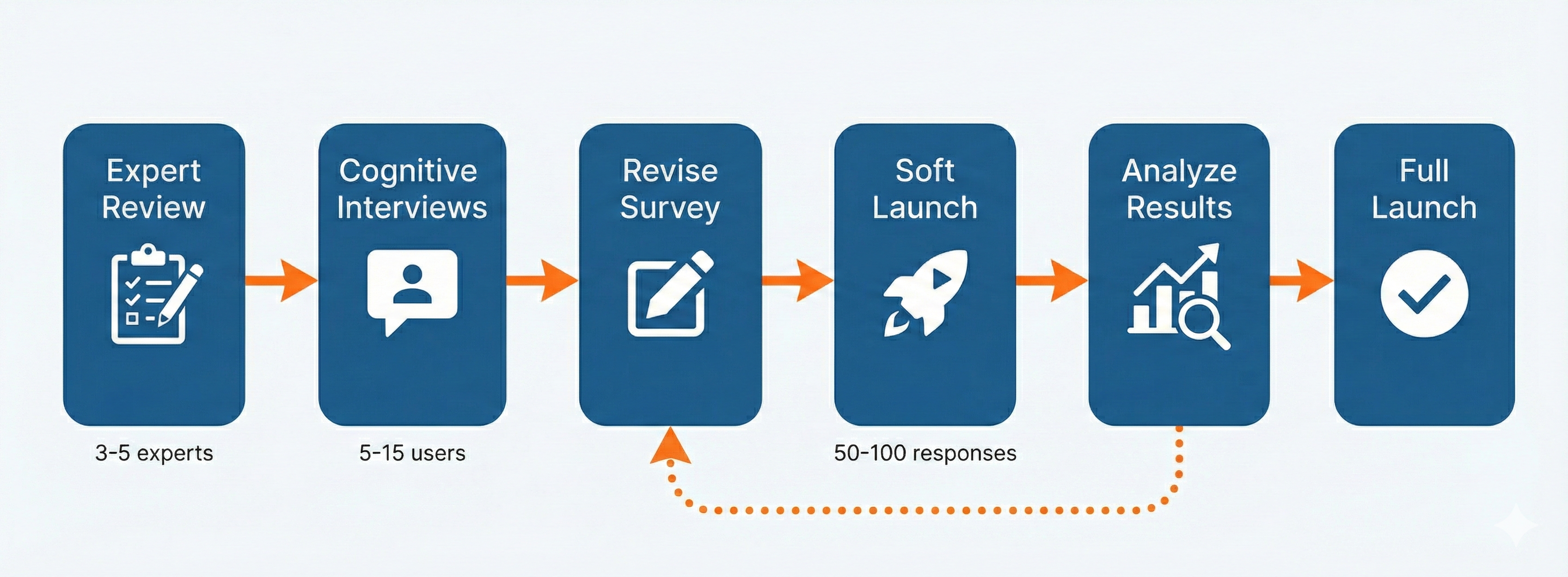
For surveys where quality matters, follow this sequence: start with expert review (3-5 experts), then cognitive interviews (5-15 users), revise based on findings, soft launch to 50-100 respondents, analyze results, and iterate if needed before full launch.
Presser et al. (2004) found that 30% of survey questions are revised after cognitive testing. That's nearly one in three questions. Skipping this step means launching with known problems.
For resource-constrained projects:
1. Expert review OR cognitive interviews (pick one)
↓
2. Soft launch (smaller, 20-50 responses)
↓
3. Quick fixes only
↓
4. Launch
What to Look For in Pilot Results
Cognitive Interview Red Flags
- Respondent asks "what do you mean by...?"
- Respondent answers a different question than intended
- Respondent says "I guess I'll pick..." (uncertainty)
- Respondent changes answer mid-response
- Respondent skips instructions or preamble
Soft Launch Red Flags
- Completion rate below 50% (unless expected for your audience)
- Median completion time 2x+ your estimate
- Drop-off spike at specific question (>10% higher than baseline)
- Response clustering at extremes (everyone picks "strongly agree")
- Impossible patterns in data (logical contradictions)
Expert Review Red Flags
- Questions that could be interpreted multiple ways
- Response scales that don't match question wording
- Missing "not applicable" or "don't know" options
- Questions that assume knowledge respondents may not have
- Double-barreled questions (two questions in one)
The False Confidence Trap
The biggest pilot testing failure isn't skipping it. It's running a pilot, finding no problems, and concluding the survey is "validated."
Pilot testing can show your survey has problems. It cannot prove your survey doesn't have problems.
A clean pilot means:
- The issues you tested for weren't present
- In the specific conditions you tested
- With the specific participants you tested
It doesn't mean:
- Your survey measures what you think it measures
- Your data will be representative
- Your results will be actionable
Pilot Testing Checklist
Before cognitive interviews:
- Written protocol for facilitator
- Recording consent (if recording)
- Probing questions prepared
- Diverse participant recruitment (not just convenient colleagues)
- Time limit established (45-60 min max)
Before soft launch:
- Analytics/tracking enabled
- Clear criteria for "go/no-go" decision
- Process for handling soft launch responses (include in final data?)
- Timeline for analysis and decision
- Plan for what changes are acceptable vs. require full restart
After pilot testing:
- Documented findings with specific quotes/examples
- Prioritized list of changes (critical vs. nice-to-have)
- Decision on re-testing after changes
- Updated survey with revisions
- Final review of logic paths after changes
When to Skip Formal Pilot Testing
Sometimes you don't need the full process:
- Simple, low-stakes surveys: A 5-question internal feedback poll doesn't need cognitive interviews
- Established instruments: Validated scales (e.g., Net Promoter Score) don't need question-level testing, though you should still test your specific implementation
- Time-critical surveys: If you must launch today, at least have one other person complete the survey and check for obvious errors
But "we're in a hurry" is the most common excuse for launching bad surveys. The time you save by skipping pilot testing is usually less than the time you waste analyzing bad data.
Pilot Testing and Survey Tools
Modern survey platforms can help with some pilot testing tasks:
- Preview modes let you test logic paths without collecting data
- Response simulation can check that all paths are completable
- Analytics dashboards show completion times and drop-off in soft launch
- Version control lets you make changes without losing pilot data
In Lensym, the graph editor makes logic testing visual. You can see all paths and trace respondent routes before any real responses.
But no tool replaces actually watching someone take your survey.
Frequently Asked Questions
How many people do I need for a pilot test?
For cognitive interviews: 5-10 typically sufficient (Nielsen, 2000). For soft launch: 50-100 responses or 5-10% of target sample, whichever is smaller.
Should pilot test responses be included in final analysis?
Generally no, unless: (1) you made no changes after soft launch, and (2) soft launch participants came from the same population as full launch. If you made changes, pilot responses answered a different survey.
What if I find problems after launching?
Minor wording changes mid-survey are sometimes acceptable. Major changes require restarting. If you find validity problems in the data, you may need to discard responses and redesign.
Is "sending to a few friends" adequate pilot testing?
Better than nothing, but not by much. Friends are rarely representative of your target population, and they're unlikely to tell you your survey is confusing.
About the Author
The Lensym Team builds survey research tools for teams that value both data quality and usability. We've learned that the surveys producing the best insights aren't the ones with the most responses, but the ones that got the questions right before launch.
On this page
Continue Reading
More articles you might find interesting

Acquiescence Bias: What It Is, Examples & How to Reduce
Acquiescence bias is the tendency to agree regardless of content. Real survey examples, why it happens, and the methods that reliably reduce it.

Anonymous Surveys and GDPR: What Researchers Must Document
GDPR's definition of anonymity is strict. Requirements for true anonymization, when pseudonymization suffices, and documentation obligations for each.

Central Tendency Bias: What It Is, Examples & How to Prevent
Central tendency bias is when respondents cluster on middle scale options. Examples, why it happens on Likert scales, and how to prevent it.