Survey Randomization: When It Helps, When It Hurts (2026)
Randomization controls order effects but has trade-offs. When to randomize questions/options/blocks, when fixed order is preferable, and implementation pitfalls.

Randomization is one of the most powerful tools in survey design. It's also one of the most misused.
The logic seems simple: if question order affects responses (it does), randomize everything. Problem solved.
Except randomizing the wrong elements creates new problems: confused respondents, broken logic, and data that's harder to analyze without being more accurate.
This guide explains what randomization actually controls, when to use it, and when leaving things in fixed order produces better data.
What Randomization Controls: Order Effects
Order effects occur when the sequence of questions or answer options influences how people respond. There are two primary types:
Primacy Effect
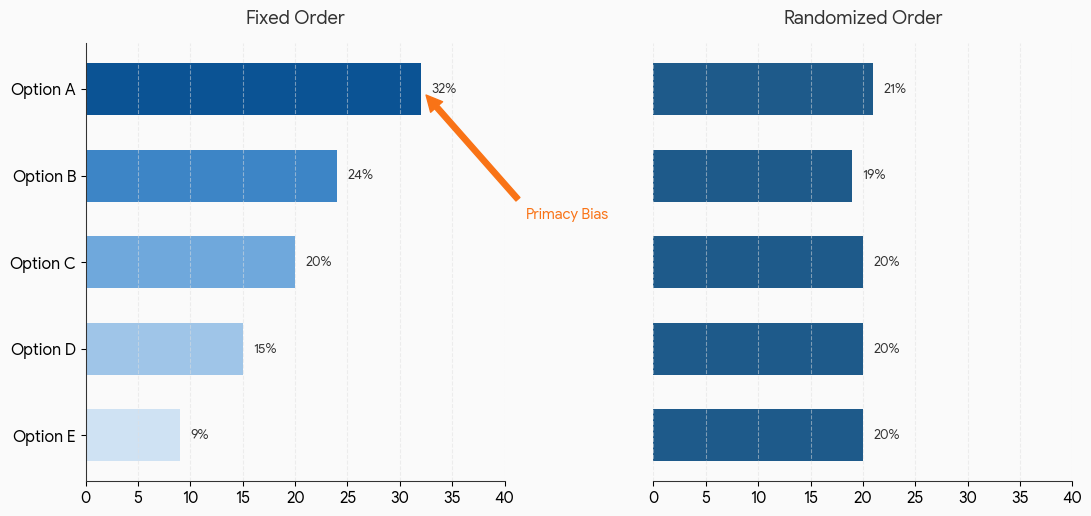
First options get chosen more often. In visual surveys (web, mobile), respondents tend to select options presented earlier in a list.
Krosnick and Alwin (1987) found primacy effects can shift response selection by 5-15% in self-administered surveys. When respondents are satisficing (answering quickly without full consideration), they're more likely to pick the first acceptable option they see.
Recency Effect
Last options get chosen more often in verbal surveys. When questions are read aloud (phone surveys, in-person interviews), the most recently heard option is more salient in working memory.
Recency effects can shift responses by 10-20% in phone surveys, though this matters less for online research where respondents see all options simultaneously.
Question Context Effects
The questions that come before a focal question affect how respondents interpret and answer it. Schuman and Presser's landmark 1981 study Questions and Answers in Attitude Surveys demonstrated that question order can shift responses by 10-25% on identical questions.
Classic example: Asking "How satisfied are you with your job?" before "How satisfied are you with your life?" produces higher life satisfaction ratings than asking in reverse order. The job question primes respondents to think about work when evaluating life overall.
We've seen teams randomize everything, including scale points, and wonder why respondents rated the same product both "Excellent" and "Poor" in the same session.
When to Randomize: The Decision Framework
Answer Option Randomization
| Element | Randomize? | Why |
|---|---|---|
| Unordered lists (brands, features) | Yes | Prevents primacy bias |
| Ordered scales (Likert, satisfaction) | Never | Breaks intuitive progression |
| Frequency scales (never → always) | Never | Logical sequence matters |
| Ranked lists (1st, 2nd, 3rd) | Never | Order is the response |
| "Other" or "None of the above" | Keep last | Convention respondents expect |
Good randomization:
Which of the following features have you used? [randomize]
- Dashboard
- Reports
- Integrations
- Mobile app
Bad randomization:
How satisfied are you? [randomize - DON'T DO THIS]
- Very satisfied
- Somewhat satisfied
- Neutral
- Somewhat dissatisfied
- Very dissatisfied
Question Randomization
| Situation | Randomize? | Why |
|---|---|---|
| Independent questions on different topics | Yes | Reduces context effects |
| Questions that build on each other | Never | Breaks logical flow |
| Sensitive questions after rapport-building | Never | Sequence matters for response quality |
| Matrix/grid items | Usually | Reduces satisficing on long matrices |
| Follow-up questions to a screener | Never | Dependent on previous answer |
Block Randomization
When you have multiple sections covering different topics, randomizing block order can reduce the influence of earlier sections on later ones.
Good block randomization:
Block A: Product satisfaction questions
Block B: Customer service questions
Block C: Pricing perception questions
[Randomize block order]
Bad block randomization:
Block A: Screening questions
Block B: Main questions
Block C: Demographics
[Don't randomize - sequence is deliberate]
How Order Effects Distort Data
Without Randomization: Systematic Bias
If you always list "Feature A" first, it will be selected more often due to primacy effect. Your data will overestimate Feature A's importance relative to features listed later.
This is a systematic error. Every response is biased in the same direction.
With Randomization: Noise Cancellation
If you randomize feature order, primacy effect still exists, but it affects different features for different respondents. The bias cancels out in aggregate.
Some people see Feature A first (and select it more). Others see Feature E first (and select it more). Across all responses, no single feature is systematically advantaged.
The Caveat: Individual Response Quality
Randomization improves aggregate accuracy at the cost of individual response consistency. A single respondent who sees "Excellent" before "Poor" may answer differently than if they'd seen the standard order.
For aggregate analysis (most surveys), this is fine. For individual-level analysis or clinical assessments, it may matter.
Randomization and Survey Logic
Here's where randomization gets complicated: it interacts with branching logic.
Problem: Randomized Questions with Dependencies
If Question B references Question A's answer, but you randomize so B sometimes appears before A, you'll have:
- Confused respondents
- Missing data
- Logic errors
Example of broken logic:
Q1: Which product do you use most? [randomized order]
Q2: Why do you prefer [piped answer from Q1]?
If Q2 is also in a randomized block and somehow appears before Q1, the piped text will be empty or wrong.
Solution: Anchor Dependent Questions
Keep dependent questions in fixed order, even within a randomized block.
[Block A - Randomized with other blocks]
Q1: Which product do you use most? [Fixed first in block]
Q2: Why do you prefer [piped answer]? [Fixed second in block]
The block can appear in random order relative to other blocks, but questions within the block maintain their logical sequence.
Testing Randomized Surveys
Randomization dramatically increases the number of paths through your survey. Pilot testing becomes more important, not less.
In your soft launch:
- Check that all randomization orders produce valid responses
- Verify piped text works regardless of presentation order
- Look for impossible response patterns (indicating logic breaks)
- Confirm completion rates don't vary wildly by randomization seed
Randomization Strategies by Survey Type
Academic Research Surveys
Recommendation: Rigorous randomization with documentation.
Academic journals increasingly require evidence of order effect mitigation. Randomize:
- All non-dependent questions
- All unordered answer options
- Block order for independent sections
Document your randomization scheme in methods section.
Customer Satisfaction Surveys
Recommendation: Selective randomization.
Randomize:
- Product/feature lists
- Attribute ratings within satisfaction matrices
- Independent question blocks
Don't randomize:
- Overall satisfaction before specific ratings (general-to-specific flow)
- NPS before follow-up questions
- Open-ended questions (keep at end to avoid priming)
Employee Engagement Surveys
Recommendation: Careful block randomization.
Engagement surveys often have sensitive questions about management, compensation, and job security. These need:
- Rapport-building questions first (fixed)
- Topic blocks in randomized order (reduces topic order bias)
- Demographics at end (fixed)
UX Research Surveys
Recommendation: Task-based ordering over randomization.
If your survey follows a user journey (onboarding → daily use → support), maintain that sequence. Context matters more than order effect mitigation.
Randomize within sections:
- Feature importance rankings
- Attribute ratings
- Competitor comparisons
Advanced: Counterbalancing vs. Randomization
For experimental research, full randomization isn't always optimal. Counterbalancing ensures equal exposure to each order combination.
Simple Randomization
Each respondent sees a random order. With 4 items, that's 24 possible orders. Some orders may be overrepresented by chance.
Latin Square Design
Each item appears in each position an equal number of times across respondents. More efficient than full randomization for detecting order effects.
Balanced Block Design
Groups of questions are rotated systematically. First third of respondents see ABC order, second third see BCA, final third see CAB.
When to use counterbalancing: When you need to measure order effects, not just neutralize them. When sample size is small and random variation could skew results.
Implementation Checklist
Before enabling randomization:
- Identified which elements are truly independent
- Verified no piped text or logic dependencies will break
- Tested all possible paths (or a representative sample)
- Confirmed scales and ordered lists are NOT randomized
- Kept "Other" and "N/A" options in expected positions
- Documented randomization scheme for analysis
After soft launch:
- Checked completion rates don't vary by randomization seed
- Verified response distributions look similar across orders
- Confirmed no impossible response patterns
- Validated that analysis code handles randomized data correctly
What Survey Tools Handle (and Don't)
Modern survey platforms offer randomization features, but implementation varies:
What most tools do well:
- Answer option randomization
- Question randomization within pages
- Block/section randomization
What many tools struggle with:
- Anchoring specific options (keeping "Other" last while randomizing others)
- Partial randomization (randomize items 1-5 but keep 6-7 fixed)
- Nested randomization (randomize within blocks AND randomize blocks)
- Recording what order each respondent saw (critical for analysis)
What to verify:
- Does your tool record presentation order in the data?
- Can you anchor specific options while randomizing others?
- Does randomization work correctly with skip logic?
In Lensym, randomization settings are visible in the graph editor, so you can see exactly which paths are randomized and verify logic connections remain valid. For a comprehensive framework on evaluating which tools support proper randomization controls, see Survey Tools for Academic Research: What Features Actually Matter.
Frequently Asked Questions
Should I randomize all my questions?
No. Only randomize questions that are truly independent. Dependent questions, screeners, demographic questions, and anything with a logical sequence should stay fixed. Randomize when primacy/recency bias would distort your results.
Does randomization affect data quality?
It improves aggregate accuracy by neutralizing order bias. Individual responses may be slightly less consistent since each person sees a different order. For most research, the aggregate improvement outweighs individual inconsistency.
How do I analyze data from randomized surveys?
If your tool records presentation order, you can analyze whether order affected responses. For most purposes, analyze the data normally. The randomization has already neutralized order effects in aggregate. Only examine order effects directly if you suspect they're large enough to matter.
Can randomization break my survey?
Yes, if you randomize questions with dependencies. Always test that piped text, skip logic, and display logic work correctly regardless of presentation order. A soft launch is essential for randomized surveys.
About the Author
The Lensym Team builds survey research tools for teams that value both data quality and usability. We believe survey design should be visible and testable, including randomization logic that's often hidden inside black-box settings.
On this page
Continue Reading
More articles you might find interesting

Acquiescence Bias: What It Is, Examples & How to Reduce
Acquiescence bias is the tendency to agree regardless of content. Real survey examples, why it happens, and the methods that reliably reduce it.

Anonymous Surveys and GDPR: What Researchers Must Document
GDPR's definition of anonymity is strict. Requirements for true anonymization, when pseudonymization suffices, and documentation obligations for each.

Central Tendency Bias: What It Is, Examples & How to Prevent
Central tendency bias is when respondents cluster on middle scale options. Examples, why it happens on Likert scales, and how to prevent it.